Can anyone suggest how to fix this slow spin-up problem?
Seagate Iron Wolf 8TB ST8000VN004I see several complaints about that drive being slow to spin-up, the
Can anyone suggest how to fix this slow spin-up problem?
Java Jive wrote:
Seagate Iron Wolf 8TB ST8000VN004I see several complaints about that drive being slow to spin-up, the
Can anyone suggest how to fix this slow spin-up problem?
manual says 23s (typ) to 30s (max), so I suspect there's nothing you can
do to the drives themselves.
in your grub.cfg maybe experiment with boot_delay=xxx values in ms to
delay all the kernel messages?
Having successfully upgraded my two primary QNAP 251+ NASs, I've handed down two of the HDs to the Zyxel NSA221s NASs that were my original backup solution. The disks are Seagate Iron Wolf 8TB ST8000VN004, originally from Amazon ...
https://www.amazon.co.uk/dp/B07SZVVBBK
... but they are giving problems in their new home, or, I should say, housing.
The problem is the same for each, they spin up too slowly to be found as the NSA221 boots, so after a cold boot I have to reboot, so that then they can be found on the reboot. Once that is done, they seem to be perfectly satisfactory, and, despite the NAS specs saying that they only work up to a max of 4TB per disk, I'm actually getting the full (nominal) 8TB added to the capacity of the other Toshiba HDs which have always been free of such problems.
I've had similar problems in the past with other Seagate HDs in these NASs, which at the time I got around by using a reboot flag in a rather convoluted manner, and which now won't work anyway because I have since configured the NASs to use the combined disk space of the two disks as one large virtual HD volume, which means that now I have nowhere to write a reboot flag unless both HD are running and found at boot, in which case I wouldn't need to write it anyway. I might be able to get round this by using RAM, but it would need some investigation as to what would survive a reboot.
This reboot requirement will be easy to forget and should be avoidable by making the system wait longer for the disks to spin up. Setting aside the problem of altering firmware (see next para), in a normal Linux installation, how normally would one accomplish this? A boot parameter? An /etc setting?
I have some scope for making changes, as in the past I've recompiled the firmware to be Gnu GPL and both NASs are running the result. Also the command run by UBoot is stored in an environment variable, which means that I could add a boot parameter to that fairly easily.
The Zyxel DK to build a GPL firmware dates from the Ubuntu 7 era (!), but I was still running it satisfactorily somewhere around Ubuntu 16 or 18. Also, the NASs each have a serial header which I can use to interrupt their boot and change things, though I wouldn't want to be doing that on a permanent basis, only for temporary fixes to see if they work. There are also OpenWRT versions of the firmware, but having obtained already a pretty good result from my own firmware, I haven't gone down that road, as it would be too time consuming for such old hardware.
Can anyone suggest how to fix this slow spin-up problem?
boot_delay appears to slow down kernel printouts, which is likely to be a
bit dependent on how many there are.
Instead I'd use rootdelay=30 to delay
the kernel start by 30 seconds, and then it'll boot at full speed.
Theo wrote:
boot_delay appears to slow down kernel printouts, which is likely to be a bit dependent on how many there are.
hence "experiment"
Instead I'd use rootdelay=30 to delay
the kernel start by 30 seconds, and then it'll boot at full speed.
I read that as waiting xx seconds before mounting the root fs, but if it can't see any disks, will it wait, or bail-out?
In uk.comp.os.linux Andy Burns <usenet@andyburns.uk> wrote:
Theo wrote:
Instead I'd use rootdelay=30 to delay
the kernel start by 30 seconds, and then it'll boot at full speed.
I read that as waiting xx seconds before mounting the root fs, but if it
can't see any disks, will it wait, or bail-out?
It'll pause the boot for 30 seconds at the point the root fs is mounted.
The rootfs is not on HDD, it'll be in flash, so the boot will then proceed once the 30s is up - it won't then fail for lack of a rootfs. If the discs still aren't up at the end of 30s (or 120s or whatever number you write there) then they will be missing, just as they are at the moment. But if they are not reliable enough to start given a large enough timeout then that points to a problem with the discs, rather than just a regular but slow spinup.
(if you did have your rootfs on the HDD you could use 'rootwait' to pause until the rootfs volume was ready. But that only applies for the rootfs and not other volumes)
from the sound, I was suspicious that the drives are only powered up
when the kernel loads the driver, and then the driver almost immediately expects them to be present, which would mean that this ploy wouldn't
work. However, I was game to try it, as I didn't think it could do any harm, but, as I feared, it didn't work. The delay comes long after this point, and too late to affect things.
Java Jive wrote:
from the sound, I was suspicious that the drives are only powered up
when the kernel loads the driver, and then the driver almost immediately expects them to be present, which would mean that this ploy wouldn't work. However, I was game to try it, as I didn't think it could do any harm, but, as I feared, it didn't work. The delay comes long after this point, and too late to affect things.
A wild thought (which I can't test as I no longer run openWRT so no
u-boot device) add the normal kernel as a crash kernel, let the first
kernel boot and spin the drives up too late ... then find a way to crash
it, so the crash kernel starts up affer the drives are spinning?
I'm not sure that's an intrinsic feature of uboot - the idea of booting into something different second time around is a feature of OpenWRT I think.Crash kernels aren't an openẀRT thing, just a Linux thing, I'm sure
~ # /zyxel/sbin/fw_setenv bootdelay 120
The difference is that this is prior to the kernel booting so the SATA
driver does not fire up. However, if spinup only happens when the driver begins talking to the drive then this won't help.
I suppose another option if that happens is to try to talk to the SATA drive in uboot, which might commence spinup. Docs: https://github.com/u-boot/u-boot/blob/master/doc/README.sata
maybe the 'sata info' command is enough to wake the HDD, and even if it
fails you can then 'sleep 30' or something while the drive spins up, and
then boot Linux.
(I'm assuming the Zyxel firmware will let you edit the u-boot command
script, not just the u-boot environment variables)
On 2025-05-06 15:07, Theo wrote:
~ # /zyxel/sbin/fw_setenv bootdelay 120
The difference is that this is prior to the kernel booting so the SATA driver does not fire up. However, if spinup only happens when the driver begins talking to the drive then this won't help.
Yes, I tried 20 seconds, so now the message ...
Hit any key to stop autoboot:
... displays for 20 seconds instead of the 3 seconds previously, but
this did not help because the HDs didn't spin up upon power on, only
when the driver loaded.
I suppose another option if that happens is to try to talk to the SATA drive
in uboot, which might commence spinup. Docs: https://github.com/u-boot/u-boot/blob/master/doc/README.sata
maybe the 'sata info' command is enough to wake the HDD, and even if it fails you can then 'sleep 30' or something while the drive spins up, and then boot Linux.
(I'm assuming the Zyxel firmware will let you edit the u-boot command script, not just the u-boot environment variables)
I may look into this, though I think the best solution would be to fix
the short delay in the SATA driver module, and I'm trying to find a
suitable place in the source files to do that. Meanwhile, a simpler possibility would be to write the autoreboot flag into the UBoot environment, because that doesn't need the HDs to be found to provide storage, and would survive a reboot. I may try this as a temporary fix, until and if I can investigate a better solution.
Are you sure this delay isn't just the drive set to spin down when not used? Perhaps they boot in the spun-down state. When you try to access a drive that's spun down, the system will often hang waiting for it to spin up.
Since the kernel wants to read the partition table stored on the disc I'm
not surprised if it hangs if the drive isn't spinning, and maybe times out.
The simplest way to adjust it with a Windows tool like SeaTools - there's
now a version for Linux and a bootable USB version too.
On 2025-05-07 15:50, Theo wrote:
Are you sure this delay isn't just the drive set to spin down when not
used?
Perhaps they boot in the spun-down state. When you try to access a drive >> that's spun down, the system will often hang waiting for it to spin up.
Since the kernel wants to read the partition table stored on the disc I'm
not surprised if it hangs if the drive isn't spinning, and maybe times
out.
The simplest way to adjust it with a Windows tool like SeaTools - there's
now a version for Linux and a bootable USB version too.
Some boxes set that OFF timeout themselves, not in the disks, so that it
is impossible to modify. At ten minutes of no activity, they power down
the disks.
Having successfully upgraded my two primary QNAP 251+ NASs, I've handed
down two of the HDs to the Zyxel NSA221s NASs that were my original
backup solution. The disks are Seagate Iron Wolf 8TB ST8000VN004, originally from Amazon ...
https://www.amazon.co.uk/dp/B07SZVVBBK
... but they are giving problems in their new home, or, I should say, housing.
The problem is the same for each, they spin up too slowly to be found as
the NSA221 boots, so after a cold boot I have to reboot, so that then
they can be found on the reboot. Once that is done, they seem to be perfectly satisfactory, and, despite the NAS specs saying that they only work up to a max of 4TB per disk, I'm actually getting the full
(nominal) 8TB added to the capacity of the other Toshiba HDs which have always been free of such problems.
I've had similar problems in the past with other Seagate HDs in these
NASs, which at the time I got around by using a reboot flag in a rather convoluted manner, and which now won't work anyway because I have since configured the NASs to use the combined disk space of the two disks as
one large virtual HD volume, which means that now I have nowhere to
write a reboot flag unless both HD are running and found at boot, in
which case I wouldn't need to write it anyway. I might be able to get round this by using RAM, but it would need some investigation as to what would survive a reboot.
This reboot requirement will be easy to forget and should be avoidable
by making the system wait longer for the disks to spin up. Setting
aside the problem of altering firmware (see next para), in a normal
Linux installation, how normally would one accomplish this? A boot parameter? An /etc setting?
I have some scope for making changes, as in the past I've recompiled the firmware to be Gnu GPL and both NASs are running the result. Also the command run by UBoot is stored in an environment variable, which means
that I could add a boot parameter to that fairly easily.
The Zyxel DK to build a GPL firmware dates from the Ubuntu 7 era (!),
but I was still running it satisfactorily somewhere around Ubuntu 16 or 18. Also, the NASs each have a serial header which I can use to
interrupt their boot and change things, though I wouldn't want to be
doing that on a permanent basis, only for temporary fixes to see if they work. There are also OpenWRT versions of the firmware, but having
obtained already a pretty good result from my own firmware, I haven't
gone down that road, as it would be too time consuming for such old hardware.
Can anyone suggest how to fix this slow spin-up problem?
If anyone needs a reminder, the original problem is appended below, this new thread/subthread is about my attempts to fix it.
The firmware for these Zyxel NSA221 NAS boxes is split into three binary files and a numbers of associated checksums and scripts, described in comments in an unpacking script as follows ...
# DATA_0000: header version
# DATA_0001: firmware version
# DATA_0002: firmware revision
# DATA_0101: model number 1
# DATA_0102: model number 2
# DATA_0200: core checksum
# DATA_0201: ZLD checksum
# DATA_0202: ROM checksum
# DATA_0203: InitRD checksum
# DATA_1000: kernel file, uImage
# DATA_1002: InitRD image, initrd.img.gz
# DATA_1004: System disk image, sysdisk.img.gz
# DATA_a000: executable, for some jobs before firmware upgrade
# DATA_a002: executable, for some jobs after firmware upgrade
Note that the last two are legacy scripts which with recent builds do not actually do anything.
To create a firmware file, these are packaged up into a single binary file, which is then unpacked as above when the firmware is applied. The packing and unpacking are done by shell scripts which call Zyxel cut-down versions of a program called CONV723.EXE, which themselves are called ram2bin and bin2ram.
I have the software development kit for the NASs, and several years ago built an image which works on both NASs, for which I still have the above component files, but for historical reasons lost in time cannot now seem to replicate that build from any of the existing or backed up build directories. In fact, rather strangely, none of them now produce anything that will boot, even unpacking the entire SDK afresh from scratch into a new directory and building an image from that, it too doesn't boot!
So I've been trying a different approach, that of unpacking the working build, modifying the initrd, and repacking it, but this too crashes with a kernel panic. Even if I simply unpack the initrd, and re-pack it UNCHANGED, EXACTLY AS IT WAS BEFORE, even that gives a kernel panic.
The packing is done by a script called 'makeras_gpl.sh', the most relevant section from which reads as follows:
# Updates ROM_CHECKSUM in {METADATA}, generate romfile_checksum, zyconf.tgz and zyconf.rom
./make_zyconf.sh
# Updates CORE_CHECKSUM in ${METADATA}, generate core_checksum ./make_kernel.sh
# Update ZLD_CHECKSUM in ${METADATA}, generate sysdisk.img.gz and zld_checksum
./make_sysdisk.sh
# Update INITRD_CHECKSUM in ${METADATA}, generate initrd.img.gz and initrd_checksum
./make_initrd.sh
# pack firmware with BETA version
./fw_pack -r ${METADATA} -o tlv.bin
./ram2bin -i tlv.bin -o ras.bin -e "${MODELNAME}" -t 4
mv ras.bin ${fBETA}
chmod 644 ${fBETA}
echo " ==> Beta version file ${fBETA} is created. --> ${vBETA}"
What I would have readers note is that initrd is the last subcomponent to be built, so it's difficult to see how rebuilding it separately can alter anything else, for example by having a different checksum, because everything else has already been built. The relevant section of 'make_initrd.sh' is as follows:
echo -e " \033[1;31m>> Enter Critcal Section! DO NOT CTRL+C <<\033[0m"
mv fs.initrd initrd
tar -zcf initrd.tar.gz initrd/
mv initrd fs.initrd
# Create ext2 image
mkdir initrd
dd if=/dev/zero of=initrd.img bs=1k count=8192
/sbin/mkfs.ext2 -F -v -m0 initrd.img
sudo mount -o loop initrd.img initrd/
sudo tar -zvxf initrd.tar.gz initrd
sudo umount initrd/
echo -e " \033[1;32m<< Exit Critcal Section! >>\033[0m"
sudo gzip -9 < initrd.img > initrd.img.gz
sudo rm -rf initrd
sudo rm -f initrd.tar.gz
sudo rm -f initrd.img
INITRDCHECKSUM=`./ram2bin -i initrd.img.gz -e "${MODELNAME}" -t 4 -q -f`
sed -i -e "s/^INITRD_CHECKSUM.*/INITRD_CHECKSUM\tvalue\t`echo ${INITRDCHECKSUM}`/g" ${METADATA}
I've gone through these steps individually a number of times in case I'd made mistakes, but even with unchanged initrd files, I've never got past the kernel panic, the relevant part of the dmesg log from which reads as follows:
physmap platform flash device: 00400000 at 41000000
physmap-flash.0: Found 1 x16 devices at 0x0 in 16-bit bank
Amd/Fujitsu Extended Query Table at 0x0040
physmap-flash.0: Swapping erase regions for broken CFI table.
number of CFI chips: 1
cfi_cmdset_0002: Disabling erase-suspend-program due to code brokenness.
7 cmdlinepart partitions found on MTD device physmap-flash.0
Creating 7 MTD partitions on "physmap-flash.0":
0x00000000-0x00020000 : "uboot"
mtd: Giving out device 0 to uboot
0x00020000-0x001e0000 : "kernel"
mtd: Giving out device 1 to kernel
0x001e0000-0x00380000 : "initrd"
mtd: Giving out device 2 to initrd
0x00380000-0x003f0000 : "etc"
mtd: Giving out device 3 to etc
0x003f0000-0x003fc000 : "empty"
mtd: Giving out device 4 to empty
0x003fc000-0x003fe000 : "env1"
mtd: Giving out device 5 to env1
0x003fe000-0x00400000 : "env2"
mtd: Giving out device 6 to env2
10 Dec 2004 USB 2.0 'Enhanced' Host Controller (EHCI) Driver@e7000000 Device ID register 42fa05
oxnas-ehci oxnas-ehci.0: OXNAS EHCI Host Controller
oxnas-ehci oxnas-ehci.0: new USB bus registered, assigned bus number 1 oxnas-ehci oxnas-ehci.0: irq 7, io mem 0x00000000
oxnas-ehci oxnas-ehci.0: USB 0.0 started, EHCI 1.00, driver 10 Dec 2004
usb usb1: configuration #1 chosen from 1 choice
hub 1-0:1.0: USB hub found
hub 1-0:1.0: 3 ports detected
USB Universal Host Controller Interface driver v3.0
sl811: driver sl811-hcd, 19 May 2005
usb 1-1: new high speed USB device using oxnas-ehci and address 2
In hub_port_init, and number is 0, retry 0, port 1 .....
usb 1-1: configuration #1 chosen from 1 choice
hub 1-1:1.0: USB hub found
hub 1-1:1.0: 4 ports detected
usb 1-1.2: new high speed USB device using oxnas-ehci and address 3
In hub_port_init, and number is 1, retry 0, port 2 .....
usb 1-1.2: configuration #1 chosen from 1 choice
usbcore: registered new interface driver usblp
Initializing USB Mass Storage driver...
scsi2 : SCSI emulation for USB Mass Storage devices
usbcore: registered new interface driver usb-storage
USB Mass Storage support registered.
mice: PS/2 mouse device common for all mice
i2c /dev entries driver
pcf8563 0-0051: chip found, driver version 0.4.2
pcf8563 0-0051: rtc core: registered pcf8563 as rtc0
OXNAS bit-bash I2C driver initialisation OK
md: linear personality registered for level -1
md: raid0 personality registered for level 0
md: raid1 personality registered for level 1
TCP cubic registered
NET: Registered protocol family 1
NET: Registered protocol family 17
drivers/rtc/hctosys.c: unable to open rtc device (rtc)
md: Autodetecting RAID arrays.
md: Scanned 0 and added 0 devices.
md: autorun ...
md: ... autorun DONE.
RAMDISK: Compressed image found at block 0
# Above is normal
# Below is crash
EXT3-fs: Magic mismatch, very weird !
List of all partitions:
0800 3907018584 sda driver: sd
0801 498688 sda1
0802 3906518016 sda2
1f00 128 mtdblock0 (driver?)
1f01 1792 mtdblock1 (driver?)
1f02 1664 mtdblock2 (driver?)
1f03 448 mtdblock3 (driver?)
1f04 48 mtdblock4 (driver?)
1f05 8 mtdblock5 (driver?)
1f06 8 mtdblock6 (driver?)
No filesystem could mount root, tried: ext3 ext2 vfat fuseblk
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(1,0)
# Below *would* have been a normal continuation for a successful boot
VFS: Mounted root (ext2 filesystem).
Freeing init memory: 116K
MTD_open
MTD_ioctl
MTD_read
MTD_close
MTD_open
MTD_ioctl
MTD_read
MTD_close
Mounting file systems...
MTD_open
MTD_ioctl
MTD_read
MTD_close
MTD_open
MTD_ioctl
MTD_read
MTD_close
egiga0: PHY is Realtek RTL8211BGR
Resetting GMAC
GMAC reset complete
ifconfig: bad address 'add'
Starting udhcpc ...
INITRD: Trying to mount NAND flash as Root FS.egiga0: PHY is Realtek RTL8211BGR
egiga0: link down
..egiga0: link up, 1000Mbps, full-duplex, not using pause, lpa 0xC1E1
.scsi 2:0:0:0: Direct-Access ZyXEL USB DISK 2.0 PMAP PQ: 0 ANSI: 0 CCS
Any ideas?
On 2025-05-05 10:24, Java Jive wrote:
Having successfully upgraded my two primary QNAP 251+ NASs, I've handed down two of the HDs to the Zyxel NSA221s NASs that were my original backup solution. The disks are Seagate Iron Wolf 8TB ST8000VN004, originally from Amazon ...
https://www.amazon.co.uk/dp/B07SZVVBBK
... but they are giving problems in their new home, or, I should say, housing.
The problem is the same for each, they spin up too slowly to be found as the NSA221 boots, so after a cold boot I have to reboot, so that then they can be found on the reboot. Once that is done, they seem to be perfectly satisfactory, and, despite the NAS specs saying that they only work up to a max of 4TB per disk, I'm actually getting the full (nominal) 8TB added to the capacity of the other Toshiba HDs which have always been free of such problems.
I've had similar problems in the past with other Seagate HDs in these NASs, which at the time I got around by using a reboot flag in a rather convoluted manner, and which now won't work anyway because I have since configured the NASs to use the combined disk space of the two disks as one large virtual HD volume, which means that now I have nowhere to write a reboot flag unless both HD are running and found at boot, in which case I wouldn't need to write it anyway. I might be able to get round this by using RAM, but it would need some investigation as to what would survive a reboot.
This reboot requirement will be easy to forget and should be avoidable by making the system wait longer for the disks to spin up. Setting aside the problem of altering firmware (see next para), in a normal Linux installation, how normally would one accomplish this? A boot parameter? An /etc setting?
I have some scope for making changes, as in the past I've recompiled the firmware to be Gnu GPL and both NASs are running the result. Also the command run by UBoot is stored in an environment variable, which means that I could add a boot parameter to that fairly easily.
The Zyxel DK to build a GPL firmware dates from the Ubuntu 7 era (!), but I was still running it satisfactorily somewhere around Ubuntu 16 or 18. Also, the NASs each have a serial header which I can use to interrupt their boot and change things, though I wouldn't want to be doing that on a permanent basis, only for temporary fixes to see if they work. There are also OpenWRT versions of the firmware, but having obtained already a pretty good result from my own firmware, I haven't gone down that road, as it would be too time consuming for such old hardware.
Can anyone suggest how to fix this slow spin-up problem?
On Sat, 5/31/2025 11:30 AM, Java Jive wrote:
If anyone needs a reminder, the original problem is appended below, this new thread/subthread is about my attempts to fix it.
The firmware for these Zyxel NSA221 NAS boxes is split into three binary files and a numbers of associated checksums and scripts, described in comments in an unpacking script as follows ...
# DATA_0000: header version
# DATA_0001: firmware version
# DATA_0002: firmware revision
# DATA_0101: model number 1
# DATA_0102: model number 2
# DATA_0200: core checksum
# DATA_0201: ZLD checksum
# DATA_0202: ROM checksum
# DATA_0203: InitRD checksum
# DATA_1000: kernel file, uImage
# DATA_1002: InitRD image, initrd.img.gz
# DATA_1004: System disk image, sysdisk.img.gz
# DATA_a000: executable, for some jobs before firmware upgrade
# DATA_a002: executable, for some jobs after firmware upgrade
Note that the last two are legacy scripts which with recent builds do not actually do anything.
To create a firmware file, these are packaged up into a single binary file, which is then unpacked as above when the firmware is applied. The packing and unpacking are done by shell scripts which call Zyxel cut-down versions of a program called CONV723.EXE, which themselves are called ram2bin and bin2ram.
I have the software development kit for the NASs, and several years ago built an image which works on both NASs, for which I still have the above component files, but for historical reasons lost in time cannot now seem to replicate that build from any of the existing or backed up build directories. In fact, rather strangely, none of them now produce anything that will boot, even unpacking the entire SDK afresh from scratch into a new directory and building an image from that, it too doesn't boot!
So I've been trying a different approach, that of unpacking the working build, modifying the initrd, and repacking it, but this too crashes with a kernel panic. Even if I simply unpack the initrd, and re-pack it UNCHANGED, EXACTLY AS IT WAS BEFORE, even that gives a kernel panic.
The packing is done by a script called 'makeras_gpl.sh', the most relevant section from which reads as follows:
# Updates ROM_CHECKSUM in {METADATA}, generate romfile_checksum, zyconf.tgz and zyconf.rom
./make_zyconf.sh
# Updates CORE_CHECKSUM in ${METADATA}, generate core_checksum
./make_kernel.sh
# Update ZLD_CHECKSUM in ${METADATA}, generate sysdisk.img.gz and zld_checksum
./make_sysdisk.sh
# Update INITRD_CHECKSUM in ${METADATA}, generate initrd.img.gz and initrd_checksum
./make_initrd.sh
# pack firmware with BETA version
./fw_pack -r ${METADATA} -o tlv.bin
./ram2bin -i tlv.bin -o ras.bin -e "${MODELNAME}" -t 4
mv ras.bin ${fBETA}
chmod 644 ${fBETA}
echo " ==> Beta version file ${fBETA} is created. --> ${vBETA}"
What I would have readers note is that initrd is the last subcomponent to be built, so it's difficult to see how rebuilding it separately can alter anything else, for example by having a different checksum, because everything else has already been built. The relevant section of 'make_initrd.sh' is as follows:
echo -e " \033[1;31m>> Enter Critcal Section! DO NOT CTRL+C <<\033[0m"
mv fs.initrd initrd
tar -zcf initrd.tar.gz initrd/
mv initrd fs.initrd
# Create ext2 image
mkdir initrd
dd if=/dev/zero of=initrd.img bs=1k count=8192
/sbin/mkfs.ext2 -F -v -m0 initrd.img
sudo mount -o loop initrd.img initrd/
sudo tar -zvxf initrd.tar.gz initrd
sudo umount initrd/
echo -e " \033[1;32m<< Exit Critcal Section! >>\033[0m"
sudo gzip -9 < initrd.img > initrd.img.gz
sudo rm -rf initrd
sudo rm -f initrd.tar.gz
sudo rm -f initrd.img
INITRDCHECKSUM=`./ram2bin -i initrd.img.gz -e "${MODELNAME}" -t 4 -q -f`
sed -i -e "s/^INITRD_CHECKSUM.*/INITRD_CHECKSUM\tvalue\t`echo ${INITRDCHECKSUM}`/g" ${METADATA}
I've gone through these steps individually a number of times in case I'd made mistakes, but even with unchanged initrd files, I've never got past the kernel panic, the relevant part of the dmesg log from which reads as follows:
physmap platform flash device: 00400000 at 41000000
physmap-flash.0: Found 1 x16 devices at 0x0 in 16-bit bank
Amd/Fujitsu Extended Query Table at 0x0040
physmap-flash.0: Swapping erase regions for broken CFI table.
number of CFI chips: 1
cfi_cmdset_0002: Disabling erase-suspend-program due to code brokenness.
7 cmdlinepart partitions found on MTD device physmap-flash.0
Creating 7 MTD partitions on "physmap-flash.0":
0x00000000-0x00020000 : "uboot"
mtd: Giving out device 0 to uboot
0x00020000-0x001e0000 : "kernel"
mtd: Giving out device 1 to kernel
0x001e0000-0x00380000 : "initrd"
mtd: Giving out device 2 to initrd
0x00380000-0x003f0000 : "etc"
mtd: Giving out device 3 to etc
0x003f0000-0x003fc000 : "empty"
mtd: Giving out device 4 to empty
0x003fc000-0x003fe000 : "env1"
mtd: Giving out device 5 to env1
0x003fe000-0x00400000 : "env2"
mtd: Giving out device 6 to env2
10 Dec 2004 USB 2.0 'Enhanced' Host Controller (EHCI) Driver@e7000000 Device ID register 42fa05
oxnas-ehci oxnas-ehci.0: OXNAS EHCI Host Controller
oxnas-ehci oxnas-ehci.0: new USB bus registered, assigned bus number 1
oxnas-ehci oxnas-ehci.0: irq 7, io mem 0x00000000
oxnas-ehci oxnas-ehci.0: USB 0.0 started, EHCI 1.00, driver 10 Dec 2004
usb usb1: configuration #1 chosen from 1 choice
hub 1-0:1.0: USB hub found
hub 1-0:1.0: 3 ports detected
USB Universal Host Controller Interface driver v3.0
sl811: driver sl811-hcd, 19 May 2005
usb 1-1: new high speed USB device using oxnas-ehci and address 2
In hub_port_init, and number is 0, retry 0, port 1 .....
usb 1-1: configuration #1 chosen from 1 choice
hub 1-1:1.0: USB hub found
hub 1-1:1.0: 4 ports detected
usb 1-1.2: new high speed USB device using oxnas-ehci and address 3
In hub_port_init, and number is 1, retry 0, port 2 .....
usb 1-1.2: configuration #1 chosen from 1 choice
usbcore: registered new interface driver usblp
Initializing USB Mass Storage driver...
scsi2 : SCSI emulation for USB Mass Storage devices
usbcore: registered new interface driver usb-storage
USB Mass Storage support registered.
mice: PS/2 mouse device common for all mice
i2c /dev entries driver
pcf8563 0-0051: chip found, driver version 0.4.2
pcf8563 0-0051: rtc core: registered pcf8563 as rtc0
OXNAS bit-bash I2C driver initialisation OK
md: linear personality registered for level -1
md: raid0 personality registered for level 0
md: raid1 personality registered for level 1
TCP cubic registered
NET: Registered protocol family 1
NET: Registered protocol family 17
drivers/rtc/hctosys.c: unable to open rtc device (rtc)
md: Autodetecting RAID arrays.
md: Scanned 0 and added 0 devices.
md: autorun ...
md: ... autorun DONE.
RAMDISK: Compressed image found at block 0
# Above is normal
# Below is crash
EXT3-fs: Magic mismatch, very weird !
List of all partitions:
0800 3907018584 sda driver: sd
0801 498688 sda1
0802 3906518016 sda2
1f00 128 mtdblock0 (driver?)
1f01 1792 mtdblock1 (driver?)
1f02 1664 mtdblock2 (driver?)
1f03 448 mtdblock3 (driver?)
1f04 48 mtdblock4 (driver?)
1f05 8 mtdblock5 (driver?)
1f06 8 mtdblock6 (driver?)
No filesystem could mount root, tried: ext3 ext2 vfat fuseblk
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(1,0)
# Below *would* have been a normal continuation for a successful boot
VFS: Mounted root (ext2 filesystem).
Freeing init memory: 116K
MTD_open
MTD_ioctl
MTD_read
MTD_close
MTD_open
MTD_ioctl
MTD_read
MTD_close
Mounting file systems...
MTD_open
MTD_ioctl
MTD_read
MTD_close
MTD_open
MTD_ioctl
MTD_read
MTD_close
egiga0: PHY is Realtek RTL8211BGR
Resetting GMAC
GMAC reset complete
ifconfig: bad address 'add'
Starting udhcpc ...
INITRD: Trying to mount NAND flash as Root FS.egiga0: PHY is Realtek RTL8211BGR
egiga0: link down
..egiga0: link up, 1000Mbps, full-duplex, not using pause, lpa 0xC1E1
.scsi 2:0:0:0: Direct-Access ZyXEL USB DISK 2.0 PMAP PQ: 0 ANSI: 0 CCS
Any ideas?
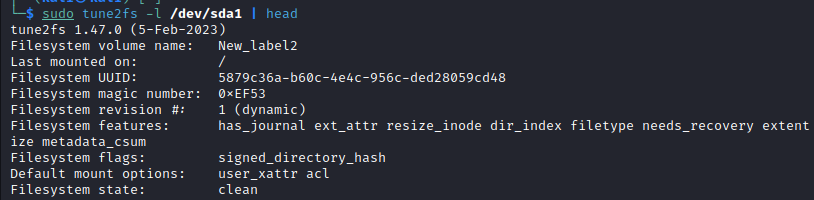
What does "tune2fs" say about the parametrics of the filesystem ?
https://media.geeksforgeeks.org/wp-content/uploads/20230929130854/Image-3.png
Have you previously removed the drive and mounted it on a technician machine ?
Maybe some damage was done to it, while it was out of the NAS and being probed.
There's got to be some reason that not even the magic number is correct.
*******
NOR flash can have bad bits in it, but that does not happen all that often. The most likely place for a failure, is segments which are flashed during each boot, and even with the high cycle count NOR flash supports, that sometimes leads to grief.
The flash load can be segmented, and each chunk has a checksum. It normally isn't possible to capture an image of an entire flash chip, and just compare it to an entire image held in hand. The validity may only be able to be determined
by knowing the start and end address of a chunk and verifying it. Automation in the tools would be the preferred way to determine the flash itself
wasn't causing a corruption. Normally, with flash devices, the loader
will halt, if a portion of what it is loading is defective.
*******Yes, perhaps, but my worst mistake seems to have been not to have copied
Processors do not normally go defective. Sometimes bad batches escape
the factory. And a NAS box is highly unlikely to have been overclocked
for most of its life.
As for your firmware kit, I would have frozen the working environment
at Ubuntu 7. In the hopes I would always have an old machine to run it on. Dragging a build environment along, say an unsupported one, on a dynamic
OS situation, that's kinda asking for trouble.
mv fs.initrd initrd
tar -zcf initrd.tar.gz initrd/
mv initrd fs.initrd
# Create ext2 image
mkdir initrd
dd if=/dev/zero of=initrd.img bs=1k count=8192
/sbin/mkfs.ext2 -F -v -m0 initrd.img
sudo mount -o loop initrd.img initrd/
sudo tar -zvxf initrd.tar.gz initrd
sudo umount initrd/
echo -e " \033[1;32m<< Exit Critcal Section! >>\033[0m"
sudo gzip -9 < initrd.img > initrd.img.gz
sudo rm -rf initrd
sudo rm -f initrd.tar.gz
sudo rm -f initrd.img
INITRDCHECKSUM=`./ram2bin -i initrd.img.gz -e "${MODELNAME}" -t 4 -q -f`
sed -i -e "s/^INITRD_CHECKSUM.*/INITRD_CHECKSUM\tvalue\t`echo ${INITRDCHECKSUM}`/g" ${METADATA}
RAMDISK: Compressed image found at block 0
# Above is normal
# Below is crash
EXT3-fs: Magic mismatch, very weird !
List of all partitions:
0800 3907018584 sda driver: sd
0801 498688 sda1
0802 3906518016 sda2
1f00 128 mtdblock0 (driver?)
1f01 1792 mtdblock1 (driver?)
1f02 1664 mtdblock2 (driver?)
1f03 448 mtdblock3 (driver?)
1f04 48 mtdblock4 (driver?)
1f05 8 mtdblock5 (driver?)
1f06 8 mtdblock6 (driver?)
No filesystem could mount root, tried: ext3 ext2 vfat fuseblk
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(1,0)
# Below *would* have been a normal continuation for a successful boot
VFS: Mounted root (ext2 filesystem).
In uk.comp.os.linux Java Jive <java@evij.com.invalid> wrote:
RAMDISK: Compressed image found at block 0
# Above is normal
# Below is crash
EXT3-fs: Magic mismatch, very weird !
List of all partitions:
0800 3907018584 sda driver: sd
0801 498688 sda1
0802 3906518016 sda2
1f00 128 mtdblock0 (driver?)
1f01 1792 mtdblock1 (driver?)
1f02 1664 mtdblock2 (driver?)
1f03 448 mtdblock3 (driver?)
1f04 48 mtdblock4 (driver?)
1f05 8 mtdblock5 (driver?)
1f06 8 mtdblock6 (driver?)
No filesystem could mount root, tried: ext3 ext2 vfat fuseblk
Kernel panic - not syncing: VFS: Unable to mount root fs on
unknown-block(1,0)
# Below *would* have been a normal continuation for a successful boot
VFS: Mounted root (ext2 filesystem).
So you appear to be making an ext2 FS and gzipping it. Do you get the 'RAMDISK: Compressed image found' in the crash scenario?
Searching on "Magic mismatch, very weird" comes up with some threads. One is hardware failure, the other is about using a non-1k blocksize with (old) mke2fs
and a 2007-era ramdisk implementation that doesn't support other than 1k: https://sourceforge.net/p/e2fsprogs/bugs/175/#b0df
Perhaps you could try -b1024 on the mkfs.ext2 command? Or experiment with other blocksizes?
Thanks, may try that later this afternoon, but what baffles me is that I think I've completely followed the procedure in the original scripts, so
why is the result so different?
BTW, my attempt to rebuild from scratch is failing also, when building Busybox:
CC loginutils/passwd.o
loginutils/passwd.c: In function ‘passwd_main’: loginutils/passwd.c:93:16: error: storage size of ‘rlimit_fsize’ isn’t known
struct rlimit rlimit_fsize;
Searching on "Magic mismatch, very weird" comes up with some threads.
One is
hardware failure, the other is about using a non-1k blocksize with
(old) mke2fs
and a 2007-era ramdisk implementation that doesn't support other than 1k:
https://sourceforge.net/p/e2fsprogs/bugs/175/#b0df
Perhaps you could try -b1024 on the mkfs.ext2 command? Or experiment
with
other blocksizes?
Thanks, may try that later this afternoon,
On 2025-06-02 13:44, Java Jive wrote:
Searching on "Magic mismatch, very weird" comes up with some threads.
One is
hardware failure, the other is about using a non-1k blocksize with
(old) mke2fs
and a 2007-era ramdisk implementation that doesn't support other than
1k:
https://sourceforge.net/p/e2fsprogs/bugs/175/#b0df
Perhaps you could try -b1024 on the mkfs.ext2 command? Or experiment
with
other blocksizes?
Thanks, may try that later this afternoon,
And it worked, adding the -b1024 parameter makes my copying manually the original procedure work! Thanks for that.
[...]
So I tried moving that bit of code to rcS, but I still can't get it to reboot. Again all the messages are correctly displayed, but no reboot actually occurs.
I now have this fully working. If it's of any interest here's the code
from rcS. If on first boot, less than 2 HDs are found, it's sets a flag
in the U-boot environment, which survives a reboot, and then does a
reboot. On the second boot, it wipes the reboot flag and carries on the boot regardless of how many HDs are found. In my case, the reboot
allows the second HD to be detected during the second boot, so the XFS storage area spread across both HDs becomes available.
${SETENV} ${REBOOTFLG} true
${ECHO} "Rebooting to try to pick up slow-spin-up drives ..."
# The following command is valid according to the help parameter, but fails
# ${UMOUNT} -a
I now have this fully working.
Java Jive wrote:
I now have this fully working.
Now, how long until the drives fail :-P
On Fri, 06 Jun 2025 12:25:35 +0100, Java Jive wrote:
[snip]
I now have this fully working. If it's of any interest here's the code
from rcS. If on first boot, less than 2 HDs are found, it's sets a flag
in the U-boot environment, which survives a reboot, and then does a
reboot. On the second boot, it wipes the reboot flag and carries on the
boot regardless of how many HDs are found. In my case, the reboot
allows the second HD to be detected during the second boot, so the XFS
storage area spread across both HDs becomes available.
[snip]
${SETENV} ${REBOOTFLG} true
${ECHO} "Rebooting to try to pick up slow-spin-up drives ..."
# The following command is valid according to the help parameter, but fails >> # ${UMOUNT} -a
Yah, assuming ${UMOUNT} resolves to something like /bin/umount, then
${UMOUNT} -a
probably would fail here. Primarily while trying to umount the filesystem that has your scripts cwd, and (because the umount failure left that filesystem still mounted) the root filesystem.
Remember, umount can't unmount an active mountpoint (one with mountspoints, open files or directories on it), and
a) your script's cwd is most likely located in one of the filesystems
mentioned in /etc/mtab (and, of course, open, because your active
process lives in that cwd),
b) / is probably in your /etc/mtab, and can't be umounted until all
the filesystems that reside on it are umounted, and
c) your use of the -a option effectively asks umount to unmount /all/
filesystems listed in /etc/mtab ("except the proc filesystem")
| Sysop: | Luis Silva |
|---|---|
| Location: | Lisbon |
| Users: | 768 |
| Nodes: | 10 (0 / 10) |
| Uptime: | 495738:10:50 |
| Calls: | 631 |
| Files: | 46,158 |
| Messages: | 15,048 |
{kind=link}